ES查询改造方案
详细阐述查询数据源从MySql迁移到ES的完整改造过程
为提升管理页面交易数据查询性能,由原先的MySql修改为ES作为数据存储中心进行查询。方案落地需要我们完成如下两点:
- MySql到ES之间的存量、实时数据同步
- 修改适配服务目前的查询逻辑,支持ES语法查询数据 而对于上面亮点的具体细化实现过程中不乏一些阻碍,下面我将会对完整的方案内容,以及方案落地过程中所遇到的阻碍和解决方案做具体的说明。目前该套方案已经在RHF-UAT环境中部署,通过SPMS4.0的交易流水查询页面即可进行体验。
一、方案说明
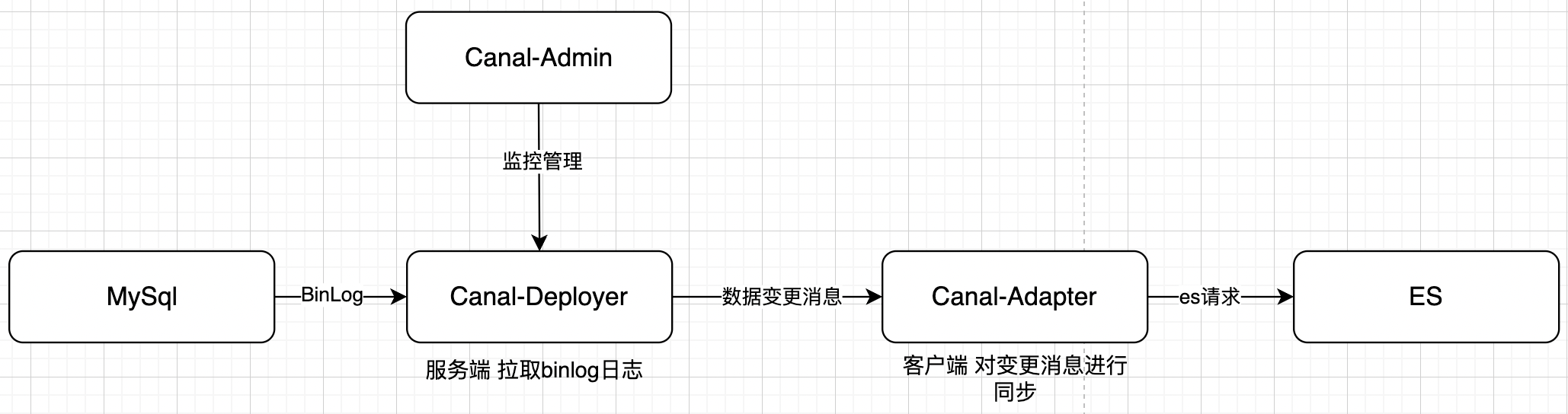
目前使用Canal Server --> Canal Adapter的同步工具,将MySql中的数据同步到ES中,支持存量和实时同步。
Canal-Deployer: 增量日志解析的中间件,通过伪装成MySql的从节点来获取binlog变更,解析为自己的消息格式后提供下游消费。
Canal-Adapter: 官方提供的数据适配器组件,是Canal Client的高级封装,用于消费Server端产生的数据变更消息,支持将数据变更消息同步至多种异构数据源中
Canal-Admin: 图形化管理后台,提供服务的在线配置监控等功能。
目前本套方案各个组件的版本说明 -- 基于RHF的当前生产版本
MySql: 8.0.34
Canal-Deployer: 1.1.8
Canal-Client: 1.1.8
Canl-Admin: 1.1.8
ES: 6.4.2
二、方案落地明细说明
2.1 数据同步
将MySql中的数据同步至ES中,我们会需要解决如下几个问题:
- 如何配置和使用Canal-Deployer、Canal-Adapter同步组件?
- ES中的索引结构需要如何定义?定义成什么样? 下面将围绕上面问题进行详细说明
2.1.1 Canal-Deployer的配置使用
1. 安装
访问官方GitHub寻找对应版本,地址:https://github.com/alibaba/canal/releases,选择canal.deployer-***.tar.gz
解压命令:tar -xzvf 文件名.tar.gz -C 目标目录
2. 配置
我将先对Canal-Deployer的内部组件名词和之间的关系进行介绍,这将对配置更好的理解。
Server: 当前的服务进程,一个Canal-Deployer代表一个Server,可以结合ZK进行集群部署
Instance(实例): 最小的工作单元(线程级别),每个Instance对应一个独立的MySQL数据库binlog订阅通道,拥有独立的解析配置、过滤规则和消费逻辑,多个Instance之间互不影响,可并行运行
基于上面的两个概念,我们知道涉及主要两个配置文件:Server 和 Instance,下面我们以单服务端、单实例为背景来说明如何进行配置。集群和多实例在单机单实例跑通了之后自己也就知道怎么配置了
- Server涉及的配置文件为:
canal.deployer-***/conf/canal.properties, 文件关键配置说明如下:(其余配置节点默认配置即可,下同)
...
# 服务的端口,客户端连接的端口
canal.port = 11111
# 实例名称 -- 多个实例使用「,」间隔 eg:example1,example2,...
canal.destinations = example
# canal admin config -- 管理后台的配置信息
canal.admin.port = 11110
canal.admin.user = admin
# 密码 - 明文 SHA-1 后得到
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
...
- Instance涉及的配置文件为:
canal.deployer-***/conf/实例名称/instance.properties,文件关键配置说明如下:(如果需要创建不同的实例则在不同的实例文件名路径下创建对应的instance.properties配置文件即可)
# 配置需要监控的数据库地址,当数据库为主从架构时可以使用「,」间隔配置地址
canal.instance.master.address=127.0.0.1:3308
# 数据库账号、密码
canal.instance.dbUsername=username
canal.instance.dbPassword=password
# 是否开启主库存活检测(默认false)当主从配置时开启使用
canal.instance.detecting.enable=false
# 配置需要监控的表,默认{.*\\..*}代表监控所有表的变动
# 语法规则 1.Java正则表达式:需注意转义(如.需写为\\.)2.两级结构:{schema正则}.{table正则}用点号分隔;3.大小写敏感: 取决于MySQL的lower_case_table_names参数
canal.instance.filter.regex=webapi_insurance\.trans_record,webapi_insurance\.refund_trans_record,webapi_insurance\.trans_record_extension3.启动/关闭
执行canal.deployer-***/bin/下的脚本,即可完成启动、关闭、重启的操作,具体的日志信息在canal.deployer-***/logs/下会进行打印
至此Canal的服务端搭建完毕可以正常使用,下面将说明客户端的配置使用。
2.1.2 Canal-Adapter的配置使用
1. 安装
访问官方GitHub寻找对应版本,地址:https://github.com/alibaba/canal/releases,选择canal.adapter-***.tar.gz
解压命令:`tar -xzvf 文件名.tar.gz -C 目标目录
版本和deployer保持一致
2.配置
Adapter的配置目录结构如下,我们主要关心的配置有两个:application.yml和监听数据库表的配置,而表的配置需要在哪个ES文件下取决于我们同步目标的ES版本。
- ...
- conf
- application.yml
- es6
- {tableName}.yml
- es7
- es8
- ...
下面我将对这两个部分的配置文件进行详细说明
/canal.adapter-***/conf/application.ymlCanal-Adapter的核心配置文件
...
canal.conf:
mode: tcp # 使用tcp的方式连接
# 失败重试次数 -1表示无限重试,重试间隔500ms
retries: 3
# 默认false,开启后在失败超过重试次数之后当前同步进程会被中断
terminateOnException: true
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 # canal服务端的ip:port 2.1.1中启动的服务
# 配置需要监听的数据库的地址、账号、密码
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3308/webapi_insurance?characterEncoding=utf8
username: dataname
password: password
canalAdapters:
# 2.1.1中说明的创建的实例名称,这个名字需要特别注意和服务端的实例匹配,不然无法成功同步
- instance: webapi4.0
groups:
- groupId: g1
outerAdapters:
# 需要与自己的es版本对上,6.*版本就写es6,7.*版本就写es7
- name: es6
# 数据同步目标的ES地址
hosts: http://127.0.0.1:9200
# 默认配置即可
properties:
mode: rest # or rest
security.auth: elastic:elastic
cluster.name: my-es特别注意:
retries: -1: 这个是需要特别注意的一个配置,默认-1表示当数据同步异常时会无限重试。如果配置指定数字例如"3",则表示重试3次之后如果还是没有成功会放弃本次数据变更的同步并对服务端进行ack,这将会到此本次数据变更永久丢失(对于同步目标来说)。同时,为了保证数据需要绝对一致的场景,官方提供了terminateOnException: true的配置用于开启当超出同步重试次数时,同步进程直接中断的功能。详见源码:AdapterProcessor#219:233行中断影响域为instance级别,如过需要重新开启可以发起如下http请求:http://127.0.0.1:8081/syncSwitch/{destination}/{status} 端口为Adpts的默认端口 destination-实例名称;status-开关状态off on-- 额外提一句这里的开关源码里利用互斥实现,该实现基于Cocurrent中的AQS实现了自己的sync BooleanMutex详见源码:SyncSwitch&&BooleanMutexgroups和outerAdapters两个配置节点下都可以配置多个,他们处理的消息实例来源都是同一个。不同的是groups之间是独立线程互不影响,而outerAdapters下是在同一个线程中。使用场景可以为针对同一个数据源,需要将相同/不同的表数据使用不同的同步频率同步至不同的目标中,如实时数据高频同步至ES中,系统的操作信息数据低频的同步至HBase中。详见源码:CanalAdapterLoader#54:91行name: es6这个配置用于标识同步目标的具体信息,可以让程序清楚具体加载哪个处理器对数据进行同步(不同的目标的具体语法不同,如es6跟es7的语法就会有差异,Adapter源码中对不同结构的数据库继承接口OuterAdapter进行不同实现,从而使上层调用统一)。具体的加载逻辑详见源码: CanalAdapterLoader#94:122行
/canal.adapter-***/conf/es6/{tablename}.yml这里的具体写明es6,是因为我当前的同步目的数据库是ES6版本,所以这边以此为例展开对该配置文件的详细说明。
trans_record.yml配置文件说明:
...
dataSourceKey: defaultDS
destination: webapi4.0 # 需要根据server端的instance名称决定
groupId: g1
esMapping:
_index: uat_webapi_all_trans_record # 需要根据索引名称决定
_type: _doc
_id: "id" # 唯一键
upsert: true # id存在则更新,否则插入
sql: SELECT
concat('webapit', record.id) AS id,
'3' AS 'system',
record.enterprise_num AS entNum,
COALESCE(record.mch_id, '') AS fgMchCode,
DATE_FORMAT(ext.notify_finish_time, '%Y-%m-%d %H:%i:%s') AS notifyFinishTime,
FROM trans_record record left join trans_record_extension ext ON record.fg_trade_no = ext.fg_trade_no AND record.enterprise_num = ext.enterprise_num
etlCondition: "where record.orderCreateTime>={}" # 批量同步时的条件
commitBatch: 3000
refund_trans_record.yml配置文件说明:(除了sql不同其余都和上述一致)
...
dataSourceKey: defaultDS
destination: webapi4.0 # 需要根据server端的instance名称决定
groupId: g1
esMapping:
_index: uat_webapi_all_trans_record # 需要根据实际的索引名称决定
_type: _doc
_id: "id"
pk: "id"
upsert: true
sql: select
concat('webapir', rtr.id) as id,
rtr.refund_no as outRefundNo,
COALESCE(record.fg_fee_settle, '0') AS fgFeeSettle,
DATE_FORMAT(ext.shipping_confirm_receive_time, '%Y-%m-%d %H:%i:%s') AS shippingConfirmReceiveTime
from refund_trans_record rtr left join trans_record record
on rtr.fg_trade_no = record.fg_trade_no and rtr.enterprise_num = record.enterprise_num
left join trans_record_extension ext
on rtr.fg_trade_no = ext.fg_trade_no and rtr.enterprise_num = ext.enterprise_num
etlCondition: "where rtr.orderCreateTime>={}"
commitBatch: 3000该部分中,遇到最大的问题是:
- 需要同步trans_record、refund_trans_record、trans_extend三张表,它们之间的关系为trans_record:refund_trans_record = 1:N ; trans_record:trans_extend = 1:1;
- 数据在ES中的是以tran_record为基准与余下的两张表通过关联展开方式存储在一个索引结构中,即存在一条交易T1,对应两天退款R1、R2以及一条扩展信息E1,那么同步后ES索引下会有三条记录,分别是
记录A: T1 E1、记录B: T1 R1 E1、记录C: T1 R2 E1,其中为了保证记录的id唯一,我们假定设置记录id为记录A: T1.id、记录B: R1.id、记录C: R2.id(目前的方案中也是这么做的) ES的数据维护,如更新删除等都会基于记录id来定位实现。对于上述的同步需求,当T1记录存在数据更新的时候,需要同时更新三条条记录,但是对于当前canal来说,binlog日志中只会存在交易记录T1的数据信息,不会有其它表的信息如R1或R2的id信息,这将会导致对于连表查询下数据无法同步问题(需要特别说明的是,普通的连表是1:N关系下只有N条记录,而当前是N+1条记录)。 对于这个问题在Canal-Adapter中的做法是: - 同时配置
trans_record.yml、refund_trans_record.yml两张表的同步配置,trans_record.yml只对交易数据进行同步,refund_trans_record.yml对退款和交易的关联查询数据进行同步。 - Canal-Adapter在对
{tablename}.yml配置文件加载时,会解析其中的sql语句,获取字段映射关系(mysql与es之间)等配置信息,并关以sql中的所有表名称作为key独立保存当前配置 - 当监听到Instance的数据变更消息时,Canal-Adapte会通过表名去匹配遍历执行所有命中的配置,并通过配置中的sql语句查询数据源,根据查询出来的数据即可完成批量的更新操作。例如: 当
refund_trans_record表数据变更时,只有refund_trans_record.yml文件中的配置会被执行,并完成对两条退款记录的更新操作。当trans_record表数据变更时,会执行trans_record.yml和refund_trans_record.yml两个配置,并完成三条记录的更新操作,因为这两个配置文件的sql都存在表trans_record。配置加载源码:ESAdapter#addSyncConfigToCache() -- dbTableEsSyncConfig变量; 遍历执行源码: ESAdapter#sync() -- configMap变量是一个MapCanal-Adapter的做法很巧妙的解决的这种复杂连表下的数据批量更新问题(刚看官方文档和源码的时候还以为这种连表的批量更新不支持,还专门改了下源码自己扩展了下,没想到是自己没有看明白),同样的对于trans_extend表的更新也是如此理解。
数据批量同步的时候请求http地址:http://127.0.0.1:8081/etl/{type}/{task}?params=param1,param2
type – 类型 hbase, es
task – 任务名对应配置文件名 mytest_person2.yml
params – etl where条件参数-配置文件中的etlCondition节点, 为空全部导入。参数需要和配置条件保持一致3.启动/关闭
执行canal.adapter-***/bin/下的脚本,即可完成启动、关闭、重启的操作,具体的日志信息在canal.adapter-***/logs/下会进行打印
至此Canal的客户端搭建完毕可以正常使用
2.1.3 Canal-Admin的配置使用
admin管理后台的使用配置比较开箱即用,Github目录下有对应的下载,配置下application.yml的数据库连接信息即可启动,启动脚本也在bin目录下。
对于Canal-Deployer服务端也只需要简单的修改对应路径下canal-deployer.*/conf/canal.properties配置文件即可,涉及的配置节点如下: (上文2.1.1中介绍canal.properties的配置文件时也有过说明)
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 2091729fef5380984e869b8c254c7283ecab23f9
admin并不是迁移过程中核心必备的组件,只不过可以让服务端管理更友好,更多的内容官方文档也有介绍,这里不进行过多的赘述。
2.1.4 ES的索引字段配置
通过es命令执行创建对应的索引结构,内容如下:
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"refresh_interval": "30"
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"refundRealRefundAmount": {
"type": "scaled_float",
"scaling_factor": 100
},
"refundRefundChannel": {
"type": "keyword"
},
"shippingConfirmReceiveTime": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}这个部分的工作难度并不高,但比较繁琐,因为需要将数据库字段与ES中的字段一一对应以及定义合适的数据类型(目前整理的es字段有100个),目前我选用的类型有三种: keyword、scaled_float、date分别用于文本、金额、时间三个类型场景,覆盖了当前的界面查询条件需求。 对于索引结构创建需要注意的点是:
number_of_shards和number_of_replicas需要分别设置为1和0,让数据在同一个节点中保存,可以防止查询时出现数据失真的情况(多个分片下聚合查询下TopN的问题)。而对于可能的数据丢失风险,因为我们目前使用的场景是界面查询使用的备库使用,所以就算极端情况下丢失也还能从数据库中恢复回来。refresh_interval表示数据的刷新时间,时间越小资源消耗越高。建议当首次批量同步时挑大一点例如30s,实时同步时可以小一点例如5s。
2.2 数据查询
当完成数据的同步后,剩下的就需要考虑如何解决将原来代码中的查询MySQL的逻辑修改为查询ES,且代码的改动幅度需要尽可能的小。目前需要改造的项目Adpts是一个多数据源,提供组内不同产品的统一查询服务,项目对查询Mapper层做了抽象和封装,统一的入参Req和返回对象Resp,不同产品间自己进行独立的实现。本次我们Es的查询方案只涉及其中一个产品,基于现有的代码分层我们只需要修改其中一个Mapper层即可。虽然代码的层级架构设计,让我们可以很好的控制代码修改范围,但是如何保持入参和返回对象一致是一个有挑战的事情。这里涉及两个困难点:
- 如何将入参转为ES的查询条件语法?
- 如何将ES的查询结果映射为返回对象? 代码需要考虑:健壮性、可维护性以及可扩展性;基于以上问题点以及希望达成的目标,下面笔者将通过文字以及部分核心伪代码来对当前的解决方案做详细陈述。
2.2.1 查询参数转为ES查询语法
对于完成Java实体查询参数转为ES查询请求这一需求,我们首先需要了解的是ES的查询语法在Java中是如何进行编写的。下面我将先通过使用示例对ES的查询语法使用做简单的说明。
2.2.1.1 Java中ES的查询使用
- 使用的es客户端为:
Rest High Level Client,对应的pom引入如下 -- 版本号与ES服务保持一致。至于选择该客户端的理由我在下面附件罗列目前了几种主流的客户端优缺点比对图
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.4.2</version> <!-- 严格匹配ES版本 -->
</dependency>
<!-- 需要显式声明以下依赖以避免冲突 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.4.2</version>
</dependency>
- 使用示例
private String esIndex = "uat_webapi_all_trans_record";
BoolQueryBuilder allParamQuery = QueryBuilders.boolQuery();
// should - 或
BoolQueryBuilder shouldQeury = QueryBuilders.boolQuery();
shouldQeury.should(QueryBuilders.termQuery("es_field_name", "queryParam"));
// 带「*」表示模糊查询
shouldQeury.should(QueryBuilders.termQuery("es_field_name2", "*queryParam2*"));
// 至少需要匹配一个
shouldQeury.minimumShouldMatch(1);
allParamQuery.shouldBuilder(shouldQeury);
// mustNot - 不等于
QueryBuilder mustNotQuery = QueryBuilders.termQuery("es_field_name3", "queryParam3");
allParamQuery.mustNot(mustNotQuery);
// must - 等于
QueryBuilder mustQuery = QueryBuilders.termQuery("es_field_name4", "queryParam4");
allParamQuery.must(mustQuery);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder()
.query(allParamQuery)
.from(0) // 起始行
.size(50) // 本次查询数量,结合from参数实现分页效果
.sort("es_field_name", "desc"); // 根据es_field_name字段降序
// 实际中使用searchAfter的方式进行翻页查询,解决深度分页查询下性能问题
// SearchSourceBuilder sourceBuilder = new SearchSourceBuilder()
// .query(allParamQuery)
// .searchAfter(esSearchAfter)
// .size(50) // 本次查询数量,结合from参数实现分页效果
// .sort("es_field_name", "desc"); // 根据es_field_name字段降序
// // 固定排序条件 - 防止翻页时的乱序
// .sort("id", SortOrder.ASC);
// 组装查询请求
SearchRequest searchRequest = new SearchRequest(esIndex);
searchRequest.source(sourceBuilder);
// 发起查询
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 获取查询结果,Map中的key:es的字段名称,value:字段对应的内容; List代表每行记录
List<Map<String, Object>> results = new ArrayList<>();
for (SearchHit hit : response.getHits()) {
results.add(hit.getSourceAsMap());
}
return results;上述伪代码对应的sql以及ES6原生查询请求分别如下:
select * from table where (es_field_name = 'queryParam' or es_field_name2 like '%queryParam2%') and es_field_name3 != 'queryParam3' and es_field_name4 = 'queryParam4';{
"from": 0,
"size": 50,
"query": {
"bool": {
"should": [
{
"term": {
"es_field_name": "queryParam"
}
},
{
"term": {
"es_field_name2": "*queryParam2*"
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"term": {
"es_field_name3": "queryParam3"
}
}
],
"must": [
{
"term": {
"es_field_name4": "queryParam4"
}
}
]
}
},
"sort": [
{
"es_field_name": {
"order": "desc"
}
}
]
}
2.2.1.2 复杂查询的转化解决方案
通过上述的伪代码,可以比较清晰的了解Java中如何进行es的查询操作方式,但是对于实际情况来说是复杂的,主要有如下几点:
- 查询参数中属性的类型多样以及ES的字段格式多样,对应条件的查询需要保持一致。例如:查询属性的格式是yyyyMMdd的String类型,而它对应的ES查询字段是时间格式,直接查询会导致查询报错;
- 查询条件不仅限于等于、不等于,还存在范围查询,如: 大于、小于、模糊匹配等。
- 存在同一个查询属性同于用于两个ES字段,例如:
(field_name1 = 'param' or field_name2 = 'param') - 需要支持参数为Collect类型时转为多值查询,例如:
field_name1 in ('param1', 'param2') - 存在根据查询参数不同的值,来做不同的查询逻辑处理,例如:
<choose>
<when test="param.allocationFlag == '0'.toString()">
and (ALLOCATIONFLAG is null or ALLOCATIONFLAG = '0')
</when>
<otherwise>
and ALLOCATIONFLAG = #{param.allocationFlag, jdbcType=VARCHAR}
</otherwise>
</choose>
- 查询参数中属性名称与ES中的字段名称不一致,导致ES请求中无从得知查询的字段名,例如:查询参数属性名
paramName,需要查询的ES字段名es_field_name
通过对场景的分析提取,可以大致的将转化需要的信息分: ES查询的字段名、查询条件、查询关系、查询类型。因此可以得到解决方案的整体思路为:
- 通过在参数参数的属性字段上标注对应的注解,注解中表明字段对应的ES字段名、查询条件等信息。
- 在Mapper层中先对查询参数对象,通过反射方式获取对应的具体查询参数信息,例如:需要查询哪些ES的字段名、每个字段的查询条件、字段的查询关系、字段的查询类型等信息
- 根据获取到的信息按照ES的查询语法,逐个转化为对应的ES查询逻辑。(如上述的示例所示) 下面将通过部分核心伪代码尽可能的展示实现思路
2.2.1.1 注解的定义
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface EsFieldName {
// 用于标记字段是否需要忽略处理
boolean ignoreFlag() default false;
// 对应需要查询的es字段名称 默认使用属性名
String name() default "";
// 查询关系
JudgingConditionEnum condition() default JudgingConditionEnum.MUST;
// 当查询逻辑为或的时候,可以配置关联字段
String[] relatedConditions() default {};
// 查询类型
EsQueryTypeEnum queryType() default EsQueryTypeEnum.ACCURATE;
}
// 查询关系
public enum JudgingConditionEnum {
MUST("1", "并"),
SHOULD("2", "或"),
MUST_NOT("3", "不包含");
}
// 查询类型
public enum EsQueryTypeEnum {
SPECIAL("0", "特殊处理,需要自己写一个扩展方法"),
ACCURATE("1", "精确"),
VAGUE("2", "模糊"),
RANGE_GT("3", "范围>"),
RANGE_GTE("4", "范围>="),
RANGE_LT("5", "范围<"),
RANGE_LTE("6", "范围<=");
}
eg:
@EsFieldName(name = "outTradeNo", condition = JudgingConditionEnum.SHOULD, relatedConditions = {"exchangeNo"})
private List<String> outTradeNoList;
对应的sql: (outTradeNo in ('') or exchangeNo in (''))2.2.1.2 保存通过反射获取的参数信息实体类
@Getter
@Setter
public class ESQueryParam {
/**
* es字段名称
*/
private String esFieldName;
/**
* 条件内容
*/
private Object queryContent;
/**
* 判断条件
*/
private JudgingConditionEnum judgingConditionEnum;
/**
* 多字段查询时的关联字段
*/
private String[] relatedConditions;
/**
* 查询类型
*/
private EsQueryTypeEnum esQueryTypeEnum;
}
/**
* 获取属性上的所有注解信息
*
* @param object 目标对象
* @return 包装后的查询所需内容
*/
private List<ESQueryParam> getFieldAnnotations(Object object) {
// 反射解析逻辑,将统一的查询请求参数object转为内部自定义的ES查询信息参数
// 解析逻辑比较常规 就是一个注解解析过程 这边就不详细说明
// ...
}2.2.1.3 ES语法的转换逻辑
/**
* 将查询参数转化为es的查询语法
*/
private BoolQueryBuilder buildQuery(List<ESQueryParam> params) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
for (ESQueryParam param : params) {
String field = param.getEsFieldName();
// 根据枚举类型添加到 BoolQuery 中
switch (param.getJudgingConditionEnum()) {
case SHOULD:
boolQuery.must(this.builderShouldQuery(field, param));
break;
case MUST_NOT:
boolQuery.mustNot(this.initBuilder(field, param));
break;
default:
// 默认使用and
boolQuery.must(this.initBuilder(field, param));
}
}
return boolQuery;
}
// 当should的查询类型时需要进行特殊构建
private BoolQueryBuilder builderShouldQuery(String field, ESQueryParam param) {
BoolQueryBuilder shouldQuery = QueryBuilders.boolQuery().should(this.initBuilder(field, param));
for (String condition : param.getRelatedConditions()) {
shouldQuery.should(this.initBuilder(condition, param));
}
// 至少需要匹配一个
shouldQuery.minimumShouldMatch(1);
return shouldQuery;
}
private QueryBuilder initBuilder(String field, ESQueryParam param) {
// 如果是特殊构造的 就直接走特殊构造逻辑了
if (EsQueryTypeEnum.SPECIAL.equals(param.getEsQueryTypeEnum())) {
return this.fieldSpecialBuilder(field, param);
}
return this.initBuilder(field, param.getQueryContent(), param.getEsQueryTypeEnum());
}
// 对不同的查询类型进行单独构造
private QueryBuilder initBuilder(String field, Object content, EsQueryTypeEnum esQueryTypeEnum) {
QueryBuilder queryBuilder;
if (content instanceof Collection) {
queryBuilder = QueryBuilders.termsQuery(field, ((Collection<?>) content).toArray());
return queryBuilder;
}
if (EsQueryTypeEnum.RANGE_GT.equals(esQueryTypeEnum)) {
queryBuilder = QueryBuilders.rangeQuery(field).gt(content);
return queryBuilder;
}
if (EsQueryTypeEnum.RANGE_GTE.equals(esQueryTypeEnum)) {
queryBuilder = QueryBuilders.rangeQuery(field).gte(content);
return queryBuilder;
}
if (EsQueryTypeEnum.RANGE_LT.equals(esQueryTypeEnum)) {
queryBuilder = QueryBuilders.rangeQuery(field).lt(content);
return queryBuilder;
}
if (EsQueryTypeEnum.RANGE_LTE.equals(esQueryTypeEnum)) {
queryBuilder = QueryBuilders.rangeQuery(field).lte(content);
return queryBuilder;
}
String contentTemp = String.valueOf(content);
if (EsQueryTypeEnum.VAGUE.equals(esQueryTypeEnum)) {
// 通过前后
contentTemp = String.format("*%s*", contentTemp);
}
queryBuilder = QueryBuilders.termQuery(field, contentTemp);
return queryBuilder;
}
/**
* 字段特殊性 - 这边优雅点的话可以类似结果映射中的typeHandler方式,但介于目前需要特殊处理的字段比较少,这边直接进行判断编写
*/
private QueryBuilder fieldSpecialBuilder(String field, ESQueryParam param) {
if ("allocationFlag".equals(field)) {
String contentTemp = String.valueOf(param.getQueryContent());
if ("0".equals(contentTemp)) {
BoolQueryBuilder boolQuery = this.initEmptyBuilder(field);
boolQuery.should(QueryBuilders.termQuery(field, "0"));
return boolQuery;
}
return QueryBuilders.termQuery(field, contentTemp);
}
if ("liquidationStatus".equals(field)) {
List<?> contentTemp = ((List<?>) param.getQueryContent());
if (contentTemp.contains("0")) {
BoolQueryBuilder boolQuery = this.initEmptyBuilder(field);
boolQuery.should(QueryBuilders.termsQuery(field, contentTemp.toArray()));
return boolQuery;
}
return QueryBuilders.termQuery(field, contentTemp.toArray());
}
log.error("【特殊处理异常】当前字段:{}配置了特殊处理,但是没有实际的处理逻辑,请检查", field);
throw new RuntimeException("特殊处理异常,请检查");
}
/**
* 查询字段内容是否为空的请求构造 -- es字段为空的查询需要多个条件判断所以这边进行了统一的封装
*/
private BoolQueryBuilder initEmptyBuilder(String field) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.termQuery(field, ""));
BoolQueryBuilder notExistsQuery = QueryBuilders.boolQuery().mustNot(QueryBuilders.existsQuery(field));
boolQuery.should(notExistsQuery);
boolQuery.minimumShouldMatch(1);
return boolQuery;
}2.2.1.4 使用方式
// 原来的查询参数参数
QueryParam param = new QueryParam();
// 通过一行代码即可完成 现有的查询参数实体到ES查询实体的转化
BoolQueryBuilder buildQuery = buildQuery(getFieldAnnotations(param));上述内容完整的陈述了查询请求的改造方案,下面将对返回结果进行详细陈述
2.2.2 返回结果映射为实体对象
从上述中的Java中ES查询的简单示例可以看到,ES查询返回的内容格式为List<Map<String, String>>格式对象,Map中的key:es的字段名称,value:字段对应的内容; List代表每行记录。与查询条件转化类似,在结果转化中遇到的主要问题如下:
- 两边字段名称,数据类型格式不一致(主要为日期格式以及金额格式)
- 数据本身是加密存储的,查询的时候需要进行解密(原有的查询逻辑中是通过注解+切面的方式进行) 那么对此,我的解决方案思路为:
- 创建注解,对字段名称不一致,数据类型格式不一致的字段进行标记。由于不同的格式转换处理逻辑不一致,在注解中指定具体的转化执行类
- 使用原有的加密注解,对识别到有解密注解的字段调用解密逻辑 同样的,我将通过核心伪代码的方式对实现方案进行具体的展示
2.2.2.1 字段映射注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface EsValueMapping {
// es字段名称 为空默认与属性名称一致
String esFieldName() default "";
// 具体的转化执行类 默认类不做任何处理
Class<? extends ValueConvertHandle> convertHandle() default BaseConvertHandle.class;
// 时间字段需要转化的格式
String srcFormat() default "yyyyMMddHHmmss";
// 一些字符串的特殊处理类型 - 用于同一个执行类下进行不同处理逻辑使用
StrFormatTypeEnum formatType() default StrFormatTypeEnum.Default;
}
public enum StrFormatTypeEnum {
Default("0", "无意义"), // 注解中必须要有一个默认值
AmountDeal("1", "es是金额格式,java是string"),
DateFormat("2", "es是ISO8601格式,java是string yyyyMMddHHmmss格式");
}2.2.2.2 核心转化类
@Slf4j
@Service
public class AutoMapping {
private Map<Class<?>, ValueConvertHandle> convertHandleMap = new HashMap<>();
private Map<Class<?>, MetaObject> metaObjectMap = new HashMap<>();
@Autowired(required = false)
private IFingardDataEncryptSpec iFingardDataEncryptSpec;
// 调用入口 - 多行数据
public <T> List<T> mapToBean(List<Map<String, Object>> maps, Class<T> tClass) {
try {
List<T> results = new ArrayList<>();
for (Map<String, Object> map : maps) {
results.add(this.mapToBean(map, tClass));
}
return results;
} catch (Exception ex) {
log.error("结果转换异常,异常原因:", ex);
throw new RuntimeException(ex);
}
}
// 调用入口 - 单行数据
public <T> T mapToBean(Map<String, Object> map, Class<T> clazz) {
try {
T bean = clazz.newInstance();
MetaObject metaObject = this.getAndCacheMetaObject(clazz);
for (MetaObject.MetaField metaField : metaObject.getFields()) {
metaField.getField().set(bean, this.convertValueByAno(map, metaField));
}
return bean;
} catch (Exception e) {
throw new RuntimeException("Map转对象失败", e);
}
}
// 转化处理
private Object convertValueByAno(Map<String, Object> map, MetaObject.MetaField metaField) {
Object esValue = map.get(metaField.getEsFieldName());
// iFingardDataEncryptSpec 为空说明当前的配置没有开启加密
if (metaField.isEncryptFlag() && esValue != null && iFingardDataEncryptSpec != null) {
// 目前加密的字段都是字符串字段
esValue = iFingardDataEncryptSpec.decrypt(null, String.valueOf(esValue));
}
esValue = metaField.getValueConvertHandle().convert(esValue, metaField);
return esValue;
}
/**
* 获取转化需要的信息 - 通过缓存的方式实现性能的提升
**/
private <T> MetaObject getAndCacheMetaObject(Class<T> clazz) {
MetaObject metaObject = metaObjectMap.get(clazz);
if (metaObject != null) {
return metaObject;
}
metaObject = new MetaObject(clazz);
metaObjectMap.put(clazz, metaObject);
return metaObject;
}
}
/**
* Map转Bean多过程的信息类
* 包括目标Bean中属性转化的处理类、对应的ES字段名称、格式类型等信息
* @author Han
* @version 1.0 2025/06/04
**/
@Slf4j
@Getter
@Setter
public class MetaObject {
/**
* 字段本身
*/
private List<MetaField> fields = new ArrayList<>();
public <T> MetaObject(Class<T> ctl) {
initMetaObject(ctl);
}
private <T> void initMetaObject(Class<T> ctl) {
for (Field field : ctl.getDeclaredFields()) {
fields.add(this.initMetaField(field));
}
}
private MetaField initMetaField(Field field) {
try {
MetaField metaField = new MetaField();
field.setAccessible(true);
metaField.setField(field);
metaField.setEncryptFlag(field.getAnnotation(EncryptField.class) != null);
String esFieldName = field.getName();
ValueConvertHandle valueConvertHandle = new BaseConvertHandle();
EsValueMapping esValueMapping = field.getAnnotation(EsValueMapping.class);
if (esValueMapping != null) {
esFieldName = StringUtils.isBlank(esValueMapping.esFieldName()) ? field.getName() : esValueMapping.esFieldName();
valueConvertHandle = esValueMapping.convertHandle().newInstance();
metaField.setDateFormat(esValueMapping.srcFormat());
metaField.setStrFormatTypeEnum(esValueMapping.formatType());
}
metaField.setEsFieldName(esFieldName);
metaField.setValueConvertHandle(valueConvertHandle);
return metaField;
} catch (Exception ex) {
log.error("对象反射解析处理异常,异常原因:", ex);
throw new RuntimeException(ex);
}
}
@Getter
@Setter
public static class MetaField {
private Field field;
/**
* 加密字段标记 true-加密 false-解密
*/
private boolean encryptFlag;
/**
* 该字段在es中映射的名称,默认与属性名称一致 - 用于字段名称与es的字段名称不一致的情况下使用
*/
private String esFieldName;
/**
* es数据源的字段类型
*/
private ValueConvertHandle valueConvertHandle;
/**
* 时间字段时需要转化为的格式 默认为:yyyyMMddHHmmss
*/
private String dateFormat;
/**
* 字符串转字符串的不同处理
*/
private StrFormatTypeEnum strFormatTypeEnum;
}
}2.2.2.3 字段映射及格式处理类
public interface ValueConvertHandle {
Object convert(Object inputOb, MetaObject.MetaField metaField);
}
// 字符串类型转为时间格式
public class StringToDateConvertHandle implements ValueConvertHandle {
@Override
public Date convert(Object inputOb, MetaObject.MetaField metaField) {
if (inputOb == null) {
return null;
}
if ("ISO8601".equals(metaField.getDateFormat())) {
OffsetDateTime offsetDateTime = OffsetDateTime.parse((String) inputOb, DateTimeFormatter.ISO_OFFSET_DATE_TIME);
return Date.from(offsetDateTime.toInstant());
}
return DateUtil.parse((String) inputOb, metaField.getDateFormat());
}
}
// double类型转为金额格式
public class DoubleToBigDecimalConvertHandle implements ValueConvertHandle {
@Override
public BigDecimal convert(Object inputOb, MetaObject.MetaField metaField) {
if (inputOb == null) {
return null;
}
Double inputObTemp = (Double) inputOb;
return BigDecimal.valueOf(inputObTemp).setScale(2);
}
}
// 基础实现
public class BaseConvertHandle implements ValueConvertHandle {
@Override
public Object convert(Object inputOb, MetaObject.MetaField metaField) {
return inputOb;
}
}2.2.2.4 使用方式
// 注解的使用 - 将ES中的double格式数据转为Bean中的金额格式
@EsValueMapping(convertHandle = DoubleToBigDecimalConvertHandle.class)
private BigDecimal discountAmount;
@Autowired
private AutoMapping autoMapping;
// 也是通过一行代码即可完成对查询结果的转化
List<PRCommonInfoDTO> queryResults = autoMapping.mapToBean(queryResults, PRCommonInfoDTO.class);至此,上述内容对ES查询改造方案进行了完整详细的陈述,其中包括了对同步组件使用的说明,代码改造过程中遇到的问题以及对应的解决方案。从需求的提出、到方案的论证以及实际落地过程中,通过不过解决遇到的问题,让我在大数据量查询方案实践能力得到提升。目前该套方案已经在UAT环境中部署运行,对于文章中感兴趣或有问题及不足的地方可以联系本人进行讨论和订正。
三、附件
目前主流ES客户端的优缺点比对
| 客户端类型 | 适配版本 | 是否官方 | 特点简述 |
|---|---|---|---|
| Rest High Level Client | ES 6.x ~ 7.x | ✅ 是 | 语法清晰,逐步废弃 |
| Java API Client | ES 7.15+ / 8.x | ✅ 是 | 新一代,类型安全,推荐新项目使用 |
| Spring Data Elasticsearch | 多版本匹配 | ✅ 是 | Spring 生态集成,声明式开发,适合 CRUD 场景 |
| Jest Client | ES 6.x | ❌ 否 | 简单易用,但已不维护 |
| Low Level REST Client | 所有版本 | ✅ 是 | 低级别封装,自由度高,复杂度也高 |
选择Rest High Level Client的理由是:目前生产ES服务的版本为6.4.2,且当前的查询逻辑较为复杂; |
adapter的源码项目结构说明
将对本地同步涉及到几个模块进行说明,方便在看到的时候有方向
- canal-canal-1.1.8
- client-adapter
- launcher/main # 启动入口、生命周期控制
- java
- loader
- AdapterProcessor # 适配处理器, 具体的处理类
- CanalAdapterLoader#init() # 代码查看的入口 **
- resources
- application.yml
- common # 公共类
- es6x # es请求执行模块
- es7x
- es8x # 不同的版本
- hbase # 同步到hbase时调用
- ...
通过CanalAdapterLoader#init()入口,一步步点进入看就好了,代码逻辑比较清晰简单。源码down下来之后可以本地运行调试下,会熟悉的更快(配置文件修改resoureces下的application.yml即可,配置的方式参数上文中的配置描述)。
Last Updated: June 15, 2025
CC BY-NC-SA 4.0
